Qiitaの投稿をサジェストするシステムを開発するため(唐突ですが、作ろうと思っているのです)に利用を検討している、implicitというpythonの協調フィルタリングライブラリを試していて、以下のサンプルプログラムを動かしてみたのだが(--suggestとオプションをつけるとユーザへのサジェストのコードが走る)、
このサンプルプログラムはLast.fmという聴いている楽曲もしくはアーティスト(へのレーティング)に基づいておすすめのアーティスト(楽曲も、だったかも)をサジェストするサービスで得られた以下のデータセット
・約30万アイテム(アーティスト)x 約35万ユーザ、の行列データ(疎行列)
・要素数(レーティングの数)は約1700万
を、(デフォルトで利用されるimplicitではALSと呼んでいるモデルでは、)Matrix Factrazationか、Factorazation Machineかどちらか(どっちかは実装を読まないと分からん)で次元削減(して元に戻す)する前処理(fit関数)を行ってから、ユーザごとにサジェストの処理をするのだけど、使うモデルやパラメータにはよるものの、デフォルトのモデル・パラメータで、
・前処理: 約20sec
・サジェスト: 約5ms/user
*1
という処理時間だったので、サジェストするページのリストは夜間のバッチで作成しておくようにしようかと考えていたが、Webサーバの上のアプリケーションプロセス(というのが正しいのだろうか)の中で、hd5形式で用意しておいた疎行列データを最初にロードして、前処理(fit関数を呼ぶ)して(前処理した結果を保持しているモデルのオブジェクトがpickle等でシリアライズできるようなら、それをオブジェクトとしてロードする形にできるが、まだ調べてない)、リクエストのタイミングでサジェストするという設計でもいけるかなーとか考えているが、どうだろうなー。
WebフレームワークはDjango Frameworkを利用予定。
ただ、上記のデータセットをメモリに載せると700MB程度は食うようなので(※前処理・サジェスト処理はデータセットを置いておくメモリ以外はほとんどメモリ食わない)、Qiitaのデータセットは上記データセットより疎だろうし、同程度の行列サイズを想定しているものの、集められるユーザ・投稿の情報はもっと少ない気がする・・・ので、データセットのメモリ上でのデータサイズはもっと小さくなるだろう、ということを考慮しても、アプリケーションプロセスの数は1~3プロセス程度に制限する必要はありそう(運用予定の個人鯖はメモリ2GBしか積んでないので)。
で、Django Frameworkに限らんけども、その手のフレームワークって、1~3プロセス程度でそれなりの数のユーザをさばけるんだっけ。
(アプリケーションプロセスはGILを解放するネットワークI/OやDBアクセスのためのI/Oが多くを占めていて、なんちゃってマルチスレッドでも複数リクエストをさばける、という仕組みと認識しているが・・・)
なお、上に書いた実行結果は最近組みなおした自作デスクトップでの実行結果で、運用予定のマシンとはスペックが違います(自作デスクトップの方が上)・・・。
■自作デスクトップ(上記実行結果を得たマシン)
Ryzen 5 2600 3.4GHz 6core, 16GBメモリ
Windows10 64bit上の、WSL Ubuntu 16.04 (Windowsネイティブのpython環境では動作しなかった)
(今回の実行では利用されていないが、Radeon RX570 8GB GDDR5)
■運用予定の鯖(KVMを使っているっぽいVPS)
Xeon Silver 4114 2.20GHz 仮想2コア, 2GBメモリ
CentOS 6 (x86_64)
以下は動作させている時の出力
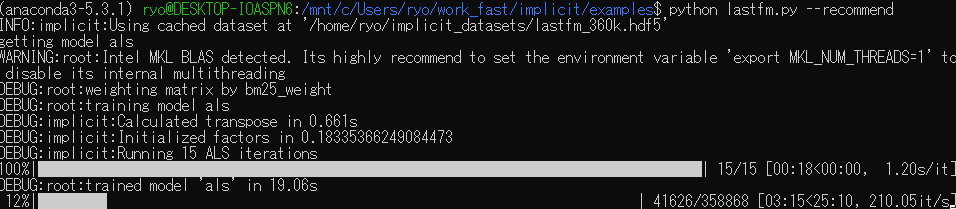 gyazo.com
gyazo.com
さて、この設計でいけるかなー
(まずはVPS環境での性能を見ろ、という話はある)
追記(19/11/25 6:30):
運用予定のVPSで実行してみたところ、下のようになった。
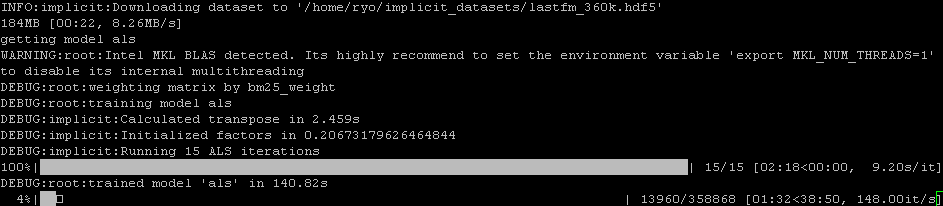 gyazo.com
gyazo.com
行列分解なんかのマルチコアで並列化できるところはコア数が減っているのもあるのか、自作デスクトップ機と比べて7倍程度遅くなっているが、サジェスト処理自体は 200user/sec ぐらいだったのが、150user/sec に落ちたぐらいなので、単体コア性能で速度が決まるところは、75%程度までの速度低下(=1.3倍程度時間がかかるようになった)だけで済んだようだ。
前処理は一度やれば済む処理で、重要なのはサジェスト処理なので、この結果は悪くない。