先日参加したOSC名古屋2010で、USP社さんのユニケージ開発手法に関する講演を聞いた。
その中で、パイプを使えば、自然にマルチコアの性能を引き出せるできるよ!という話があって、非常に興味深かったので、自分でも試してみた。
#最初は、同じくUSP社の中の人に聞いたマシンを跨いだパイプのテクニック*1を使って、なんちゃって分散データ処理やーと意気込んだが、結構大変そうだったのでひとまず断念して、今回のネタをやってみた
講演で行われたデモでは、集計処理みたいな事をやっていたけど、今回はbcを使った計算処理を行ってみる。
まず、こんなスクリプトを書く。
#! /bin/bash # make_data.sh for (( i=0 ; i<1000000 ; i++ )) do echo "sqrt ( sqrt ( $((RANDOM)) ) )" >> input.txt done
このスクリプトで、bc用の計算式をたくさん作る。
各計算式は適当な数にsqrtを2重にかけるというもの。
生成。
$sh make_data.sh
続いて実験。
上の入力データも使いつつ、7重にネストしたsqrtを2通りの方法で計算する。
- 方法1. 1つのbcプロセスで計算を行うもの。
2重sqrtデータ => sedで7重sqrtの計算式に変換 => bcで評価 => 答えGet♪(今回は余計なオーバヘッドを避けるため/dev/nullへリダイレクト)
-
-
- #最初から7重sqrtのデータを作ることもできるが、方法2と同じ条件で評価するためにsedでの処理を入れている。
-
- 方法2. もう一つbcプロセスを使って2プロセスで計算を行うもの。
2重sqrtデータ => bc(1)で評価 => 計算の途中結果たくさん => sedで5重sqrtの計算式に変換 => bc(2)で評価 => 答えGet♪(上記に同じ)
方法1
実験開始。
まず1プロセスで計算する、方法1。
利用したマシンは開発機のThinkpad X60。
Core2Duo搭載のデュアルコアマシン。
% time cat input.txt | sed -e 's/.*/sqrt ( sqrt ( sqrt ( sqrt ( sqrt ( & ) ) ) ) )/' | bc > /dev/null cat input.txt 0.00s user 0.03s system 0% cpu 43.152 total sed -e 's/.*/sqrt ( sqrt ( sqrt ( sqrt ( sqrt ( & ) ) ) ) )/' 2.97s user 0.08s system 7% cpu 43.288 total bc > /dev/null 39.55s user 0.30s system 91% cpu 43.334 total
43.334秒。
負荷はこんな感じ。1コアを使い切って計算している様子。
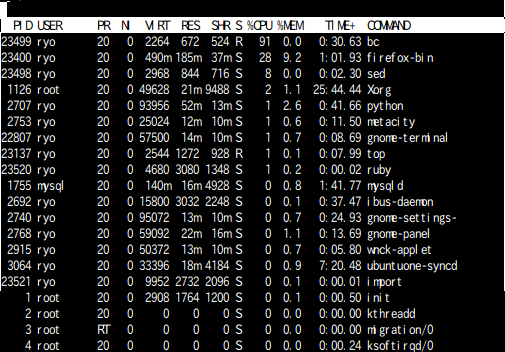
方法2
続いて、2プロセスで計算する、方法2。
打ち込むコマンドとしては、sedの前にbcを一つ挟んだだけ。
% time cat input.txt | bc | sed -e 's/.*/sqrt ( sqrt ( sqrt ( sqrt ( sqrt ( & ) ) ) ) )/' | bc > /dev/null cat input.txt 0.00s user 0.04s system 0% cpu 24.876 total bc 20.55s user 1.43s system 87% cpu 24.996 total sed -e 's/.*/sqrt ( sqrt ( sqrt ( sqrt ( sqrt ( & ) ) ) ) )/' 1.50s user 0.65s system 8% cpu 25.357 total bc > /dev/null 19.90s user 0.37s system 79% cpu 25.385 total
24.996秒。おおお早くなってる!!!
+73%の高速化。
負荷はこんな感じ。ちゃんと2コア使って計算している。
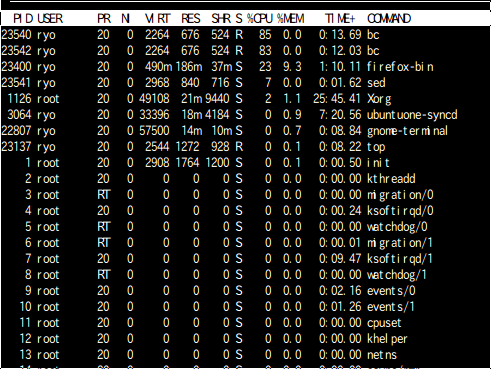
まとめ
というわけで、パイプをうまく使うとマルチコアの性能を引き出すことができる場合もあるらしい。
皆さんも、パイプライン化できるアプリがあったら、シェルでお手軽並列化してみてはいかが?
(蛇足)
驚きのユニケージ開発手法についてはこちら。
- ・USP研究所
- ・スピードがすべてを駆逐する良品計画の情報システムを支える「ユニケージ開発手法」とは
- ・有限会社ユニバーサル・シェル・プログラミング研究所26 ノード(CPU208 コア)を直列接続したパイプライン計算機による、高速情報処理技術の実用化に関する研究に着手
シェルスクリプトだけでシステムを組むかは別として、小さなプログラム群のパイプライン処理でシステムを構成するという方法論は、これからのマルチコア時代でブレイクする可能性はあるんじゃないかなと思う。
もちろん、何でもかんでも、どんなシステムでもそんな書き方できるわけじゃないだろうけど、業務システムにおいて、(多分)多くを占める、勘定処理(?)や集計処理が書けるだけでも、その意義は大きいのではないか。
#そもそも、今の業務システムって、マルチコアやらSMPなシステムにどの程度最適化されているんだろうか。リクエスト単位で並行処理できるような単純なケースはできていても、その各リクエスト内とか、他のケースは全然という感じなんじゃないかな。と予想。どうでしょ?